Image Reader (OCR) Chrome Extension
 chrome extension Download")
-
Chrome Extension Page
-
Total Number of Extension users:30K +
-
Reviewed by :23 Chrome Users
-
Author Name:
-
['sevina.lucia@gmail.com', 'Sevina']
Image Reader (OCR) extension helps you easily get words out of any image. It uses an open-source OCR library called Tesseract. Tesseract.js is an open-source JavaScript library and is made via an Emscripten port of the famous Tesseract OCR Engine written in C and C++. Please visit (https://github.com/naptha/tesseract.js) to get more info. To work with this addon, simply open the addons interface and load your image via the file selector (top section). Before using the addon, please make sure to select the appropriate OCR language. Default OCR language is set to English. Note: this addon uses the 'https://github.com/naptha/tessdata/tree/gh-pages/' GitHub repo to fetch language data required for the OCR operation. Language data packs are very large and cannot be included in the addon package. To report bugs, please fill the bug report form on the extensions homepage (https://mybrowseraddon.com/image-reader.html).
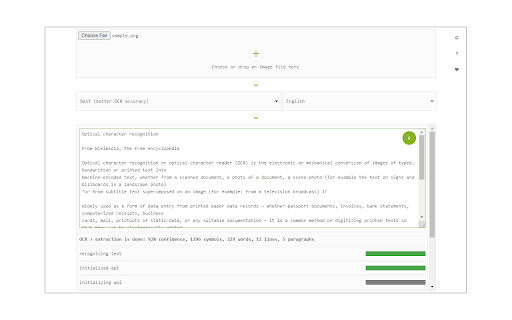
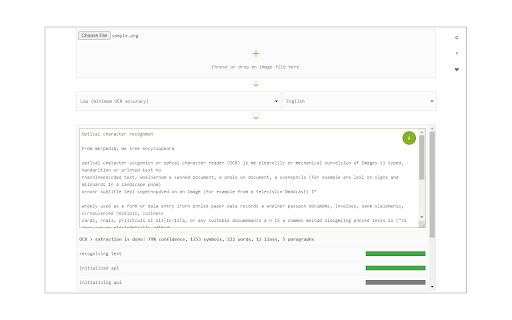

How to install Image Reader (OCR) chrome extension in chrome Browser
You can Follow the below Step By Step procedure to install the Image Reader (OCR) Chrome Extension to your Chrome Web browser.
- Step 1: Go to the Chrome webstore https://chrome.google.com/webstore or download the extension Image Reader (OCR) Chrome Extension Download from https://pluginsaddonsextensions.com
- Step 2: Now search for the Image Reader (OCR) in Chrome Webstore Search and click on the search button.
- Step 3: click on the Image Reader (OCR) Chrome Extension Link
- Step 4: in the next page click on the Add to Chrome button to Download and Install the Image Reader (OCR) extension for your Chrome Web browser .
Image Reader (OCR) Chrome extension Download
Looking for a method to Image Reader (OCR) Download for Chrome then this download link is for you.It is the Image Reader (OCR) Chrome extension download link you can download and install Chrome Browser.
Download Image Reader (OCR) chrome extension (CRX)
-
A Fast and simple document scanner app with high quality text output.
-
A powerful optical character recognition (OCR) extension to capture and convert images to text
-
This tool is actually text scaner that capture active tab's target area and extract text from it.
-
Highlight, copy, edit, and translate text from any image on the web.
-
Quote arbitary images on the web as markdown text
-
Copy, paste and translate text from any image, video or PDF.





